
Introduction
This project provides an instant java cluster, a batch-processing application for tasks written in Java with automated class distribution.
Once upon a while one needs to process a more computationally-demanding tasks. There are many batch-based solutions like the Sun Grid Engine (SGE), Debian Clusters, Rocks, or the discontinued OpenMosix project. However, they are somehow too heavy-weight, sometimes complicated to bring into life or might be unsuitable for other reasons.
If you are a Java developer who needs an instant access to computational power of multiple machines, this might be the library you are looking for.
Requirements
Java 1.5+ ports 6000 and 6001 open for RMI communication running MySQL database (will not be necessary after switching to Apache Derby/JavaDB)
Usage
There are three sides of the cluster - the server, the evaluation terminals and the client using the system.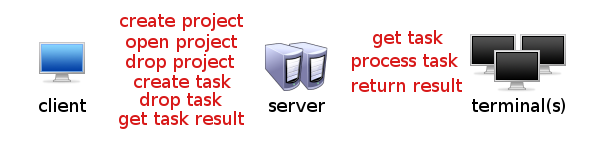
Client
The client side represents the gateway to the cluster. Services of the cluster are used through the ClusterInterface. There are methods to create/attach/drop a project, obtain its status and progress, and of course to add/get/remove tasks to be processed by the terminals.
There are two very important steps in deploying a project.
A main class of the project is a class implementing
the task to be evaluated. It is a class implementing the ClusterTask
interface, where the body is evaluated within the process
method, the arguments and settings for the task are passed-in as
argument and the result is yielded as the return value.
Project libraries is a list of classes required by the main class. These libraries (and jars) are uploaded onto terminals to ensure correct and error-less evaluation of the main class. If you forget to append a class into this list, the ClassNotFoundException is raised on the terminal and the tasks is returned in the ERROR state. In such case, you can obtain the reason by reading appropriate field from the Task.
Server
The server takes care of the tasks created by the user(s) and theclass
files and jars needed by the task to be processed. The
process scheduling is performed in the FIFO way - tasks are processed in
the order as they were inserted, there are no priorities or queues or
other complicated stuff.
Terminal
Evaluates tasks defined by the users. Calls the
ClusterTask.process() method of the task's main class. When
an exception is thrown during instantiation of any of the user's classes
or during the task's run, the task is returned back to server with the ERROR
state and the stacktrace can be then obtained on the client by one
method of the Task
object.
Number of concurrently evaluated tasks on a terminal depends on number of cpu-cores on a particular machine. It means that if you have a 4-core CPU, 4 tasks can be evaluated in 4 separate threads on that machine at the same time.
Deployment
There are some configuration options to be set before you run your cluster. You can find them in the/conf directory. Furthermore,
you need to create the database according the DDL file in the downloaded archive
and grant access permission according the configuration file. Then, to
run the server or terminal(s), just execute the appropriate script(s)
according to your needs.
Code Examples
MyClusterTask.java
The MyClusterTask.java shows a simple class implementing the ClusterTask interface, becoming thus the main class of our artificial clustered project. It accepts as argument number of loops which should perform and returns a string with the information on duration of these loops.
The argument and return value can be any kind of structure derived from the Object class.
The only requirement is that it MUST IMPLEMENT the java.io.Serializable interface (!).

MyClusterApplication.java
The MyClusterApplication.java demonstrates how to access the cluster services.
Initially, we need to log in (mainly in order identify ourselves and not to delete anyone else's data; the password is not taken into account at this moment), we check if our logging-in procedure has been done correctly (in this stage the connection to the server is established and if this returns false or even throws an exception, something is obviously wrong). If the user does not exist in the database, it will be created.
Then we tell the server we want to work with/open a project called "my new cluster project". As a result of that, now the interface knows the current project and all the other methods of the ClusterInterface will affect only this project.

At this moment there can still be some tasks being evaluated. Therefore we test the project status. In case the status is NEW, it means that the project has not been defined before and we need to define the project main class and list of classes the main class is going to use.

Now we create our tasks. We specify argument(s) for each task and create them. When our tasks are defined, we launch the evaluation. After the project has been started, it is still possible to add tasks on the fly.

While waiting for the project to finish, we can either check the project's progress or even add new or process tasks that have already been evaluated. Once a project comes into the FINISHED state, the tasks are no longer being evaluated, even if they are in the NEW state. In such case, the project must be restarted as show in the previous snippet.

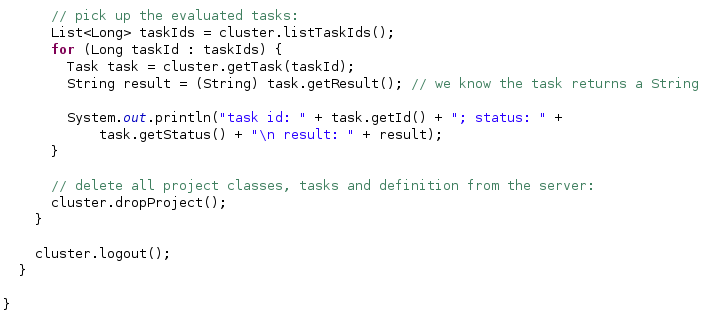
When the project is done, we can pick up the tasks and get the results. To be tidy, it is good to drop the project when we finish and also to logout before our code ends.
And that's it! :)